 ·
·
 ·
·
 ·
·
·
·
Computer sind Rechenmaschinen, die nachträglich schreiben gelernt haben. Darum speichern sie innerlich alle Informationen – auch Texte – als Zahlenreihen ab. Jeder Buchstabe entspricht einer Zahl.
Die 26 Standardbuchstaben von A bis Z, die Ziffern und die häufigsten Satzzeichen werden auf allen PCs der Welt einheitlich mit dem ASCII-Code verschlüsselt, darum hat man mit diesen Zeichen auch nie Probleme. Der ASCII-Code war ursprüglich für Fernschreiber (Telex) entwickelt worden. Nationale Sonderzeichen wie ä, ö, ü, ß, ń oder š sind darin nicht vorgesehen.
Das modernste und sauberste Verfahren zur Codierung internationaler Sonderzeichen ist Unicode. Hier entspricht jedes Zeichen, das irgendwo auf der Welt gebraucht wird genau einer Zahl, und diese Zuordnung gilt einheitlich überall auf der Welt. Da es jedoch auf der Welt Tausende verschiedener Schriftzeichen gibt, reichen dafür die bisher üblichen 8 Bit Speicherplatz pro Zeichen nicht aus. Darum wird jedes Unicode-Zeichen durch eine Folge von 16 Bits (2 Bytes) repräsentiert.
Die neueren Versionen von MS Windows und MS Office arbeiten durchweg mit Unicode, aber viele ältere Systeme und Programme beherrschen noch keinen Unicode. Und sogar bei manchen neuen Programmen machen Hersteller sich nicht die Mühe, Unicode zu integrieren, weil es ein bisschen aufwändiger ist und die meisten Kunden keinen besonderen Wert darauf legen.
Ein großer Nachteil von Unicode ist der Speicherverbrauch: Jede Textdatei, jede Zeichenkette, auch wenn sie überwiegend Standard-ASCII-Zeichen enthält, wird durch Unicode auf die doppelte Größe aufgebläht. Dem gegenüber bietet das (auf Unicode basierende) Codierungsverfahren UTF-8 mehr Kompatibilität zum Standard-ASCII-Code und spart Speicherplatz – zumindest dann, wenn ein Text überwiegend aus Standard-ASCII-Zeichen besteht und nur wenige Sonderzeichen enthält. Standard-ASCII-Zeichen werden bei UTF-8 wie gehabt in einem Byte als Zahl zwischen 32 und 127 codiert. Sonderzeichen werden als Folge von zwei oder drei Bytes codiert, wobei jedes Byte einen Wert > 128 hat, damit man es von Standard-ASCII-Zeichen unterscheiden kann.
In der Abbildung rechts sehen Sie die Rohform eines Textes, der mit UTF-8 codiert wurde. Wenn Sie einen Text in solch unleserlicher Form erhalten haben, können Sie ihn mit dem Penzeng.de-Codewandler entschlüsseln.
Die URI-Codierung (Unified Resource Identifier) wird gebraucht, um Sonderzeichen und Satzzeichen als Anhang oder Bestandteil einer Internetadresse (URL) verwenden zu können: Alle Zeichen, die normalerweise nicht in einer URL auftauchen dürfen werden hier durch eine zweistellige hexadezimale Zahl mit vorangestelltem „%“-Zeichen ersetzt. Sonderzeichen, die nicht zum ASCII-Standardzeichensatz gehören werden vorher nach dem UTF-8-Verfahren in eine Folge von 2 oder 3 Bytes verwandelt, und diese werden dann in hexadezimale Zahlen mit vorangestellten Prozentzeichen umgewandelt.
In dieser Abbildung sehen Sie z. B., wie in der tschechischen Wikipedia
die Kategorie přírodní vědy (d.h. Naturwissenschaften) als URI codiert wird.
URI-Zeichenketten können Sie ebenfalls mit dem Codewandler entschlüsseln.
HTML (Hypertext Markup Language) dient hauptsächlich zum Erstellen von Internetseiten. Inzwischen wird dieses Format auch gern für E-Mails, elektronische Handbücher und andere computerbasierte Texte verwendet. Internationale Sonderzeichen werden in HTML entweder als benannte Zeichen oder als Unicode-Zahlen umschrieben.
Mehr dazu erfahren Sie im nächsten Exkurs.
Auch HTML-codierte Texte können mit dem Codewandler
entschlüsselt werden.
Eines der ältesten Codierungsverfahren für Sonderzeichen, das auf heutigen PCs zum Teil immer noch verwendet wird besteht darin, lediglich den Zahlenbereich von 128 bis 255 mit speziellen Schriftzeichen zu belegen. Das ist die sogenannte Codeseite. Da nicht alle Schriftzeichen der Welt in so eine kleine Codeseite passen, beschränkt man sich auf die Zeichen, die man für die eigene Sprache (und nahe stehende Nachbarsprachen) braucht:
|
Deutsche Windows-PCs verwenden standardmäßig diese westliche Codeseite: |
Polnische und tschechische Windows-PCs verwenden standardmäßig diese mitteleuropäische Codeseite: |

|

|
| Der Zeichenvorrat dieser Codeseite genügt, um u. a. Deutsch, Englisch, Französisch, Spanisch, Portugiesisch, Dänisch und Isländisch zu schreiben. Die meisten polnischen und tschechischen Zeichen sind darauf jedoch nicht enthalten. | Der Zeichenvorrat dieser Codeseite genügt, um u. a. Polnisch, Tschechisch, Slowakisch, Ungarisch und Rumänisch zu schreiben. Viele französische, spanische und italienische Zeichen sind darauf jedoch nicht enthalten. |
Versucht man nun, z. B. einen tschechischen Text mit westlicher Codeseite darzustellen,
bekommt man verkehrte Zeichen:

|
Die Tschechen bekommen denselben Text richtig dargestellt
weil ihre Computer mit mitteleuropäischer Codeseite arbeiten:

|
Wenn man nun diese beiden Codeseiten miteinander vergleicht, stellt man fest, dass einige Zeichen auf beiden Seiten gleich sind. Dazu zählen u. a. auch die deutschen Buchstaben ä, ö, ü und ß. Diesen Umstand können wir uns zu Nutze machen: Unsere deutschen PCs sind zwar standardmäßig „westlich“ eingestellt, da aber ä, ö, ü und ß auch genauso auf der mitteleuropäischen Codeseite vorhanden sind, können wir ohne größere Probleme auch diese Codeseite verwenden.
Wählen Sie im Startmenü Systemsteuerung / Regions- und Sprachoptionen. Die Regionalen Einstellungen lassen Sie lieber so wie sie sind; wählen Sie die Karteikarte Erweitert. Dort, unter der Rubrik Sprache für Programme, die Unicode nicht unterstützen ist standardmäßig Deutsch (Deutschland) eingestellt. Damit wird die westliche Codeseite benutzt. Wenn Sie hier statt dessen Polnisch oder Tschechisch auswählen, wird auf Ihrem Computer die mitteleuropäische Codeseite aktiviert. Es spielt keine Rolle, ob Sie Polnisch oder Tschechisch wählen; die Codeseite ist in beiden Fällen die gleiche. Wenn Sie den Dialog mit OK beenden, bekommen Sie die Mitteilung, dass der Computer neu gestartet werden muss. Eventuell wird auch die Windows-Installations-CD zum Nachladen bisher nicht installierter Komponenten benötigt.
Nach dieser Umstellung bekommen Sie die die meisten polnischen und tschechischen Texte am Bildschirm sofort richtig angezeigt, denn Ihr Computer ist in dieser Hinsicht nun so eingestellt wie ein polnischer oder tschechischer Computer. Dennoch können Sie Ihr deutsches Tastaturlayout mit deutschen Umlauten und „ß“ ohne Einschränkung wie gewohnt weiter verwenden.
Nach meinen bisherigen Erfahrungen schadet es nicht und stört meistens auch nicht, wenn man einen deutschen PC mit mitteleuropäischer Codeseite betreibt. Es kann jedoch in älteren Anwendungsprogrammen, beim Datenaustausch oder bei der Korrespondenz mit westeuropäischen Partnern vorkommen, dass nun z. B. französische oder dänische Buchstaben plötzlich verunstaltet oder unleserlich erscheinen. Da haben wir dasselbe Codeseiten-Problem wie vorher, nur diesmal nicht mit östlichen, sondern mit westlichen Sprachen. Eine perfekte Lösung, die für alle Sprachen gleichermaßen taugt ist mit heutiger Software noch nicht uneingeschränkt machbar. Denn für alle Nicht-Unicode-Anwendungen können Sie ja immer nur eine Codeseite auswählen. Sie müssen sich also entscheiden, ob Sie Ihren Computer eher „westlich“ oder eher „mitteleuropäisch“ ausrichten wollen.
Eine andere Möglichkeit gibt es leider nicht. Falls Sie sich zu einer „mitteleuropäischen“ Ausrichtung Ihres Computers nicht entschließen können, werden Sie hier und da mit vermurksten slawischen Zeichen leben müssen. Sie können aber den Codewandler auf dieser Website verwenden, um entstellte Texte lesbar zu machen.
Ein spezieller Mangel ist mir noch aufgefallen: Wenn man mitteleuropäische Codeseite eingestellt hat, startet MS Outlook den E-Mail-Editor stets mit tschechischem Tastaturlayout, obwohl das deutsche Layout als Standard festgelegt ist.
Auf dieser Europakarte sehen Sie, welche Sprachen zu welcher Codeseite passen:
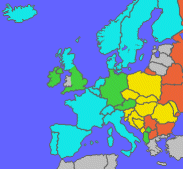
| Westlich | |
| Mitteleuropäisch | ||
| Westlich oder Mitteleuropäisch | ||
| Kyrillisch | ||
| Sonstige | ||
Hier endet der Exkurs. Weiter geht’s im Haupttext.
© Penzeng.de