 ·
·
 ·
·
 ·
·
·
·
Computers were originally calculating machines. Later, they have become able to process texts. For this reason, they internally store all information, even texts, as numbers. Every letter is represented by a number.
ASCII code was originally developed for telex and has become a standard widely used in most computers. In ASCII code, the 26 letters from A to Z, the digits and the most frequent punctuation marks are encoded into numbers between 0 and 127. But ASCII code cannot represent letters with diacritic marks that are used in many national languages.
Unicode is a modern approach to overcome the limitations of ASCII code. It uses larger numbers to unambiguously represent all letters of all scripts that are used anywhere in the world. Thus, handling foreign langugages is easy with Unicode, but it requires twice as much disk space.
New versions of MS Windows and MS Office embrace Unicode, but many older systems and programs do not. Even in new programs, software developers sometimes do not include Unicode, because it is more costly, and many customers do not attach importance to this.
A great disadvantage of Unicode is that it consumes so much disk space. When a text largely consists of standard latin characters, and there are only a few special characters in it, you can save much disk space by using the UTF-8 encoding. With most European languages, this is usually the case.
In UTF-8, standard characters are encoded just like ASCII, using one byte per character. Special characters from the larger Unicode character set are encoded in two or three bytes. In the figure on the right side, you can see the raw form of a text encoded with UTF-8. If you have receiced a text in such an illegible form, you can decode it with our automatic character switcher.
The URI (Unified Resource Identifer) encoding is used to include foreign characters or punctuation marks as parts or appendixes of internet addresses (URL): All characters that are usually forbidden in a URL are encoded into two digit hexadecimal numbers with prefixed “%” signs. Characters that do not belong to the standard ASCII character set are encoded with UTF-8 first, and then further encoded into hexadecimal numbers with percent signs.
In this figure, you can see for example the name přírodní vědy (that means natural sciences) encoded as URI in the Czech Wikipedia. You can decode such URI strings with our automatic character switcher, too.
HTML (Hypertext Markup Language) was originally designed to create web pages. But meanwhile this format has become popular for e-mails, help files and other computer based texts, too. In HTML, any foreign characters can be encoded as character entity references or as numeric character references. Our automatic character switcher can decode these references, too.
One of the oldest ways to encode national special characters is using the numbers between 128 and 255. This space is called code page. code pages are old fashioned, but sometimes still used in modern PCs. One code page is not enough to contain all characters of the world, so there are many different code pages for different languages.
|
Anglo-American and German Windows-PCs use this western code page by default: |
Polish and Czech Windows-PCs use this middle European code page by default: |

|

|
| The characters in this code page suffice e.g. for English, German, French, Spanish, Portugese, Danish and Icelandic. But many characters needed for Polish and Czech are not included. | The characters in this code page suffice e.g. for Polish, Czech, Slovak, Hungarian and Romanian. But some characters needed for French, Spanish or Italian are not included. |
| When a text was encoded with middle European code page and is decoded with western code page, then false characters appear in it: | A text encoded with middle European code page has to be decoded with the same code page, too, then all characters appear correctly: |

|

|
So if you have trouble because your computer uses the wrong code page, you can solve this by telling it to use the right one:
In System Control / Language Options / Extended, you can select a language for programs that do not support Unicode. If any western language is set here, Windows will use the western code page. On the other hand, if you select any middle European language, e.g. Polish or Czech, Windows will use the middle European code page for non-Unicode applications. There is only one code page for all middle European languages, so it does not matter which one of these languages you select. When you change this selection, Windows may ask you to insert the installation CD to install further components.
After you made this setting, most polish and czech texts will be shown correctly, because your computer is set up like a polish or czech computer. According to my experience, it is mostly harmless and safe to run a western computer with middle European code page. Only if you try to process French, Spanish or other western languages that have letters with diacritic marks, then these letters may become disfigured and illegible. There you have the same problem as before, not with eastern, but with western languages. Alas with code pages, there cannot be a perfect solution for all languages, because you have to choose one single code page, either western or middle european.
On this map, you can see which languages fit to which code page:
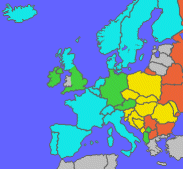
| Only Western | |
| Only Middle European | ||
| Western or Middle European | ||
| Cyrillic | ||
| Others | ||
The excursus on character encodings ends here. You can return to the main text.
© Penzeng.de