 ·
·
 ·
·
 ·
·
·
·
Most European languages (including German, Polish and Czech) are written with latin alphabet, but have some characters modified with diacritic marks (e.g. dots, umlauts, strokes, hooks…). You may face two problems when you try reading or writing these languages:
On this page, you will learn how to manage these problems. These tips especially refer to Windows XP, but in principle, they are applicable to all Windows versions since Windows 98.
There are different methods to enter foreign characters, and each one has its own advantage, so you may choose yourself which one suits best for you:
With Microsoft Word, there is a simple way to insert foreign characters into a text: Open the Symbol dialog box with the Symbol item in the Insert menu. In this dialog, select the Symbols tab, and in the Font box, select “(normal text)”. In this dialog page, you see a character table with ordinary latin characters. But when you scroll down in the table, you get a wide range of foreign characters, and when you double click one of them, the character will be inserted into your Word document.
If you use any other word processing program, not MS Word, you can anyhow select foreign characters in a similar way: Open the symbol table as a separate utility program. It is hidden somewhere in the depths of the Windows Start menu. With this tool, you can select foreign characters from a table, copy them to the clipboard, then switch to your word processing program and insert them.
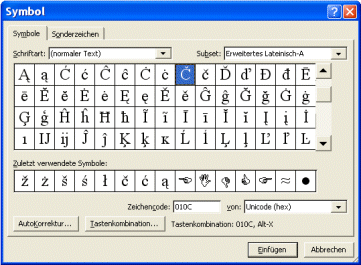
Choose a usual font like Arial or Times New Roman to have a great choice of foreign characters. With eccentric fonts, the symbol table is much smaller, and many foreign characters are not available.
If you know the decimal ASCII or Unicode number of a required character, you can type it this way: While keeping the Alt key pressed, enter the three-digit ASCII code or the four-digit Unicode on the number pad, and then release the Alt key. To enter Unicodes less than 1000, use a leading zero.
| German | Polish | Czech | |||
|---|---|---|---|---|---|
| Ä | Alt+0196 | Ą | Alt+0260 | Č | Alt+0268 |
| Ö | Alt+0214 | ą | Alt+0261 | č | Alt+0269 |
| Ü | Alt+0220 | Ć | Alt+0262 | Ď | Alt+0270 |
| ä | Alt+0228 | ć | Alt+0263 | ď | Alt+0271 |
| ö | Alt+0246 | Ę | Alt+0280 | Ě | Alt+0282 |
| ü | Alt+0252 | ę | Alt+0281 | ě | Alt+0283 |
| ß | Alt+0223 | Ł | Alt+0321 | Ň | Alt+0327 |
| „ | Alt+8222 | ł | Alt+0322 | ň | Alt+0328 |
| “ | Alt+8221 | Ń | Alt+0323 | Ř | Alt+0344 |
| ‚ | Alt+8218 | ń | Alt+0324 | ř | Alt+0345 |
| ’ | Alt+8217 | Ś | Alt+0346 | Š | Alt+0352 |
| € | Alt+8364 | ś | Alt+0347 | š | Alt+0353 |
| Ź | Alt+0377 | Ť | Alt+0356 | ||
| ź | Alt+0378 | ť | Alt+0357 | ||
| Ż | Alt+0379 | Ů | Alt+0366 | ||
| ż | Alt+0380 | ů | Alt+0367 | ||
| Ž | Alt+0381 | ||||
| ž | Alt+0382 | ||||
As long as you seldom use foreign characters, you may be satisfied with the above mentioned methods. But if you need foreign characters very often, you will probably look for a more convenient way to type more fluently. And indeed there is such way: You can switch to a foreign keyboard layout, and with that, you can type as if you had a german, polish or czech keyboard for example. But this requires some preparation: You have to choose a keyboard layout that suits you, hold your Windows installation CD ready because you will probably need to install extra components, and get used to a strange keyboard layout where many characters seem out of place. If you are willing to do this, please read this excursus:
Excursus: Switch to a foreign keyboard layout
Currently, there are two kinds of e-mails:
In traditional text-only e-mails, you should strictly avoid east european characters like č, ń or ł. Even if your e-mail program can handle them, they often become totally disfigured in transit, and the addressee will have much difficulties to read that. Nevertheless you can use this kind of e-mail to send informal messages, but if you do, you should omit the diacritic marks and use corresponding standard letters instead. Exceptions: The German characters ä, ö, ü, ß, and vowels with acute accent (á, é, í, ó, ú, ý) are quite safe to use. With š and ž, it will work in most cases, too.
The same rules roughly apply to internet visitors’ books, forums and chats, too. There are some modern systems which handle foreign characters correctly, but many others do not.
If you need to mail a text correctly with all diacritic marks, send it as HTML mail, or append it as *.htm, *.html, *.rtf or *.doc file. These formats can handle Unicode, that means, they can store and reliably reproduce any foreign characters.

When you receive e.g. polish e-mails, browse on a czech website, or process czech words with old software, the text may sometimes look like in this picture, containing false characters that would more likely fit to Spanish, Italian or Danish language, or even totally senseless and scrambled looking symbols.
If you have received such an illegible text, you can use the character switcher on this website to simply unscramble it. If you want to learn more about the reasons of this problem and how to solve it, please read this excursus:
Web pages written in foreign languages are sometimes displayed with false characters due to different encodings. But there is also another reason for this: These web pages are badly written. When HTML code is well-designed, such errors cannot happen. Good HTML code should contain nothing but standard ASCII characters. All other (special, foreign) characters should be encoded either as Character entity references or as numeric character references.
You can find a complete list of these encodings here: List of XML and HTML character entity references
If both Character entity references and numeric character references seem too cumbersome to you, then you should at least add one of these meta tags to the <head> section of your HTML file, indicating the code page you are using:
The Windows and ISO character sets are very similar, but unfortunately not absolutely identical.
Most Polish and Czech characters cannot be encoded with Character entity references, because no contemporary web browser interprets them correctly. So the only recommendable way is using these numeric character references:
Ą → Ą
ą → ą
Ć → Ć
ć → ć
Č → Č
č → č
Ď → Ď
ď → ď
Ę → Ę
ę → ę
Ě → Ě
ě → ě
Ł → Ł
ł → ł
Ń → Ń
ń → ń
Ň → Ň
ň → ň
Ř → Ř
ř → ř
Ś → Ś
ś → ś
Š → Š
š → š
Ť → Ť
ť → ť
Ů → Ů
ů → ů
Ź → Ź
ź → ź
Ż → Ż
ż → ż
Ž → Ž
ž → ž
© Penzeng.de