 ·
·
 ·
·
 ·
·
·
·
Komputery są maszynami do liczenia i pisania. Dlatego zapisują one wszelkie informacje – także teksty – w postaci szeregu liczb. Każdej literze odpowiada jedna cyfra.
26 liter podstawowego alfabetu łacińskiego od A do Z, cyfry i najczęstsze czcionki zakodowane są na wszystkich komputerach świata jednakowo kodem ASCII, dlatego z tymi znaki nigdy nie ma problemów. Kod ASCII był początkowo przeznaczony dla teleksu. Narodowe znaki specjalne takie jak ä, ö, ü, ß, ń lub š nie zostały uwzględnione.
Najnowocześniejszą i bezbłędną metodą kodowania międzynarodowych znaków specjalnych jest Unicode. Każdemu znakowi, który używany jest gdzieś na świecie, przyporządkowana jest liczba, jednakowy proces obowiązuje na całym świecie. Ponieważ jednak na świecie używa się tysiąca różnych liter, każdy znak z unicodem reprezentowany jest przez ciąg 16 bitów.
Nowsze wersje MS Windows i MS Office pracują całkowicie z unicodem, ale wiele starszych systemów i programów go nie posiada. Nawet producenci niektórych nowych programów nie starają się wprowadzać unicodu, ponieważ jest to trochę bardziej pracochłonne i większość klientów nie przywiązuje do tego wagi.
Dużą wadą unicodu jest zużycie pamięci. Każdy plik tekstowy, każdy szereg znaków, nawet jeśli zawiera głównie znaki standardowe ASCII, przez unicode zajmuje podwójnie dużo miejsca. Metoda kodowania opierająca się na unicodach, UTF-8, zapewnia większą zgodność z kodem ASCII oraz oszczędza magazyn pamięci – przynajmniej wtedy, gdy tekst składa się przeważnie ze znaków standardowych ASCII i tylko niewielu znaków specjalnych. Standardowe znaki ASCII są przy UTF-8 kodowane w jednym bajcie w postaci liczb między 32 a 127. Znaki specjalne zakodowane są jako ciąg dwóch lub trzech bajtów, przy czym 1 bajt ma wartość > 128, aby można było je odróżnić od znaków standardowych ASCII.
Na ilustracji po prawej znajduje się początkowa forma tekstu, który zakodowano metodą UTF-8. Jeśli otrzymali Państwo tekst w takiej nieczytelnej formie, mogą go Państwo rozszyfrować za pomocą konwertera kodu.
Kodowanie URI stosowane jest do zapisania znaków specjalnych i czcionek w postaci załączników lub części adresu internetowego (URL). Wszystkie znaki, które zazwyczaj nie mogą pojawić się w adresie URL, są zastępowane przez dwucyfrową liczbę poprzedzoną znakiem „%”. Znaki specjalne, które nie zaliczają się do czcionki standardowej ASCII, są przekształcane zgodnie z metodą UTF-8 w ciąg dwóch lub trzech bajtów, te z kolei zostaną przeformowane na liczby z poprzedzającym je „%”.
Na powyższej ilustracji widzą Państwo np. jak w czeskiej Wikipedii kodowana
jest kategoria přírodní vědy (nauki przyrodnicze) metodą URI.
Szereg znaków URI mogą Państwo rozszyfrować także z pomocą
konwertera kodu.
HTML (Hypertext Markup Language) służy głównie do tworzenia stron internetowych. Format ten stosowany jest też w e-mailach, elektronicznych podręcznikach i innych tekstach opierających się na komputerze. Międzynarodowe znaki specjalne są opisywane w HTMLu albo jako znaki opisane bądź liczby Unicode.
Więcej na ten temat dowiedzą się Państwo w
kolejnej dygresji.
Także teksty zakodowane w HTMLu można rozszyfrować za pomocą
konwertera kodu.
Jedna z najstarszych metod kodowania znaków specjalnych, która stosowana jest częściowo wciąż w dzisiejszych komputerach, polega na zapisaniu liczb tylko od 128 do 255 za pomocą specjalnych liter. Jest to tak zwana strona kodowa. Ponieważ nie wszystkie litery świata pasują do takiej małej zakodowanej strony, ogranicza się do tych znaków, które wykorzystywane są we własnym języku (i spokrewnionych językach sąsiadów):
| Niemieckie komputery Windows wykorzystują standardowo zachodnioeuropejskie strony kodowej: | Polskie i czeskie komputery Windows wykorzystują standardowo środkowoeuropejskie strony kodowej: |

|

|
| Zasoby znaków tej strony wystarczają do pisania m.in. po niemiecku, angielsku, francusku, hiszpańsku, portugalsku, duńsku i islandzku. Nie ma tam jednak większości znaków polskich i czeskich. | Zasoby znaków tej strony wystarczają do pisania m.in. po polsku, czesku, słowacku, węgiersku i rumuńsku. Nie ma tam jednak wielu znaków francuskich, hiszpańskich i włoskich. |
Jeśli spróbujemy przedstawić np. czeski tekst za pomocą zachodnioeuropejskich
kodów, to otrzymamy niewłaściwy zapis:

|
Czeski tekst zostanie zapisany prawidłowo, ponieważ czeskie komputery
posługują się środkowoeuropejskimi kodami:

|
Gdy porównamy ze sobą obie zakodowane strony, stwierdzimy, że niektóre znaki są takie same w obu przypadkach. Do tego zaliczają się m.in. także niemieckie litery ä, ö, ü i ß. Z tej okoliczności możemy skorzystać: niemieckie komputery mają wprawdzie standardowo „zachodnioeuropejskie“ ustawienia, ale ä, ö, ü i ß są także dostępne na środkowoeuropejskiej zakodowanej stronie, to bez większych problemów możemy używać również tej zakodowanej strony.
Wybierzcie Państwo z menu Start Systemsteuerung / Regions- und Sprachoptionen. Regionalne ustawienia najlepiej zostawić jakie są; wybierzcie opcję Erweitert Tam, w rubryce „Sprache für Programme, die Unicode nicht unterstützen” ustawiony jest standardowo język niemiecki (Niemcy). W ten sposób wykorzystywana jest zachodnioeuropejska strona zakodowana. Jeśli zamiast tego wybiorą Państwo polski lub czeski, na Państwa komputerze zostanie aktywowana środkowoeuropejska zakodowana strona. Nie gra roli, czyli będzie to polski, czy czeski; zakodowana strona jest w obu przypadkach taka sama. Jeśli zakończą Państwo ten zabieg klikając na OK, pojawi się informacja, że komputer należy ponownie uruchomić. Ewentualnie potrzebna będzie też płytka instalacyjna Windowsa do ściągnięcia elementów jeszcze nie zainstalowanych.
Po tym przestawieniu większość tekstów polskich i czeskich pojawi się na ekranie w poprawnej formie, ponieważ od tego momentu komputer jest tak ustawiony jak ten polski lub czeski. Jednak ze względu na niemiecki układ klawiatury mogą Państwo dalej pisać niemieckie umlauty i „ß“ bez ograniczeń.
Moim zdaniem nie zaszkodzi mieć niemiecki komputer ze środkowoeuropejską stroną zakodowaną. Jednak w starszych programach użytkowych, podczas wymiany danych lub korespondencji z partnerami z Europy Zachodniej, może się zdarzyć, że np. francuskie lub duńskie litery nagle zostaną zniekształcone lub będą ledwo czytelne. Jest to ten sam problem jak wcześniej, tylko teraz nie ze wschodnimi, lecz zachodnimi językami. Perfekcyjne rozwiązanie, które nadaje się do wszystkich języków w równym stopniu, nie jest z dzisiejszym oprogramowaniem możliwe bez ograniczeń. Dla wszystkich aplikacji nie-unicodowych można wybrać zawsze tylko jedną zakodowaną stronę.
Innej opcji niestety nie ma. Mogą Państwo jednak korzystać z konwertera kodu na tej stronie internetowej, aby odczytać zniekształcone teksty.
Jeszcze jedno: jeśli ustawimy komputer na środkowoeuropejską zakodowaną stronę, to MS Outlook uruchamia edytora e-maili stale z czeskim układem klawiatury, chociaż niemiecki układ jest ustawiony jako standard.
Na tej mapie Europy widzą Państwo, jakie języki pasują do których kodów:
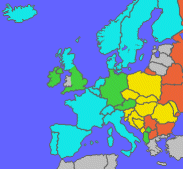
| Zachodnie | |
| Środkowoeuropejskie | ||
| Zachodnie lub Środkowoeuropejskie | ||
| Cyrylicki | ||
| Pozostałe | ||
Tutaj kończy się dygresja. Z powrotem do części głównej.
© polski.penzeng.de